To schedule a Python script or Python function in Airflow, we use `PythonOperator`.

To schedule a Python script or Python function in Airflow, we use `PythonOperator`.
Biến `context` trong airflow là biến hay sử dụng trong Airflow (`PythonOperator` with a callable function), nhưng mình rất hay quên, note lại đây để dễ dàng tra cứu.

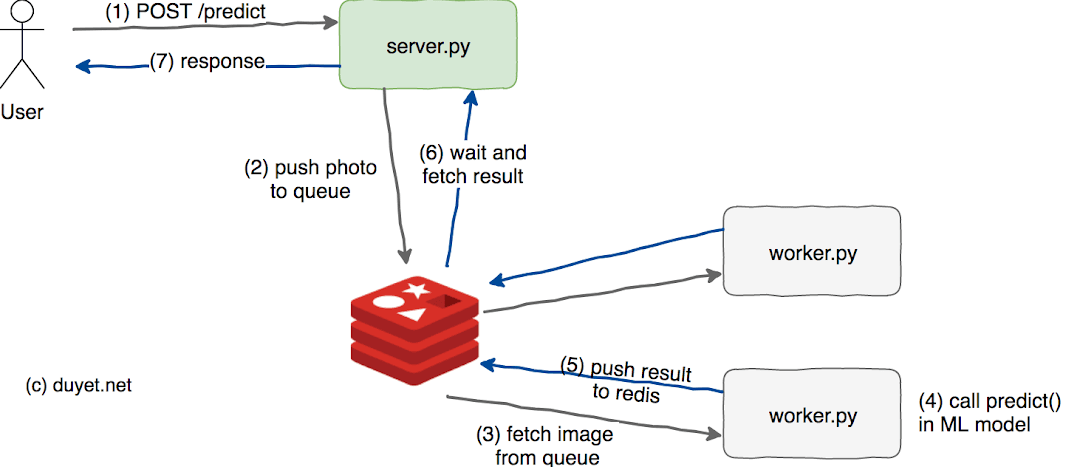
Trong bài này mình sẽ hướng dẫn deploy 1 model Deep learning, cụ thể là Keras dưới dạng một web service API. Sử dụng Flask framework python và Redis server như một Messeage Queue.
Google Colab (https://colab.research.google.com/) là một phiên bản Jupyter/iPython đến từ Google (think iPython + Google Drive), cung cấp cho chúng ta một môi trường notebook-based với backend Python 2/3 miễn phí. Google Colab rất hữu ích trong việc chia sẻ, giáo dục và teamwork trong các dự án về Machine Learning.

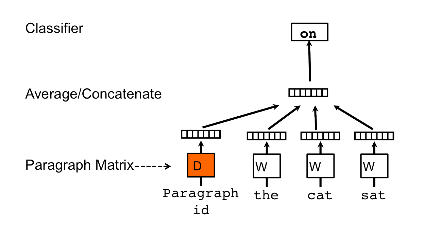
Doc2vec, ngoài từ (word), ta còn có thể biểu diễn các câu (sentences) thậm chí 1 đoạn văn bản (document). Khi đó, bạn có thể dễ dàng vector hóa cả một đoạn văn bản thành một vector có số chiều cố định và nhỏ, từ đó có thể chạy bất cứ thuật toán classification cơ bản nào trên các vector đó.
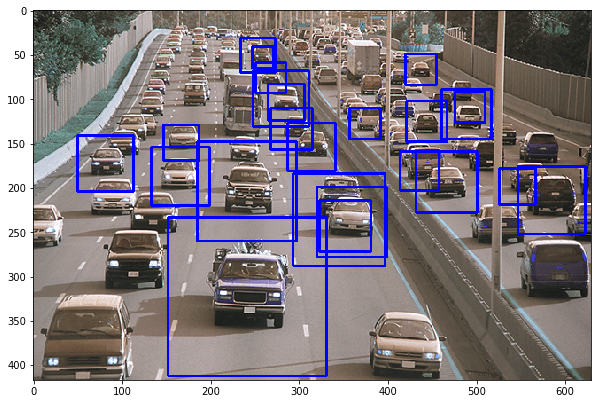
Trong bài này, mình sẽ hướng dẫn sử dụng OpenCV để nhận diện xe hơi trong ảnh (video frame) với đặc trưng HAAR, sử dụng file mô hình đã được trained.
Trong Machine Learning và NLP, phân lớp văn bản là một bài toán xử lí văn bản cổ điển, gán các nhãn phân loại lên một văn bản mới dựa trên mức độ tương tự của văn bản đó so với các văn bản đã được gán nhãn trong tập huấn luyện.
Mình nhận được nhiều phản hồi từ bài viết BigData - Cài đặt Apache Spark trên Ubuntu 14.04 rằng sao cài khó và phức tạp thế. Thực ra bài viết đó mình hướng dẫn cách build và install từ source.
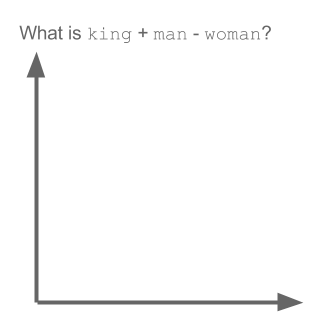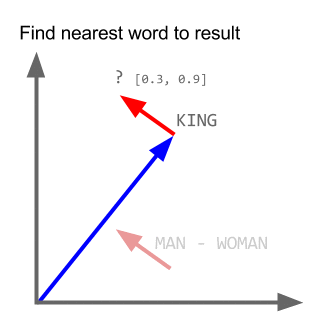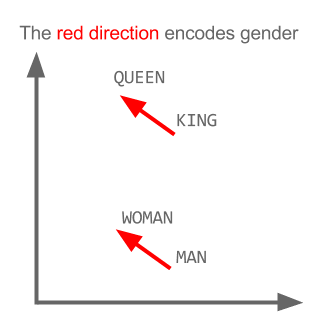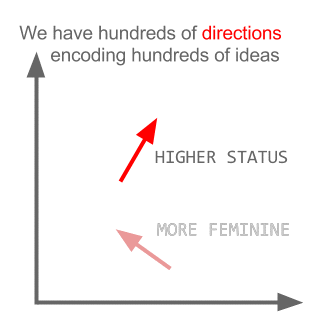
Trong các dự án gần đây mình làm nhiều về Word2vec, khá có vẻ là useful trong việc biểu diễn word lên không gian vector (word embedding). Nói thêm về Word2vec, trong các dự án nghiên cứu W2V của Google còn khám phá được ra tính ngữ nghĩa, cú pháp của các từ ở một số mức độ nào đó
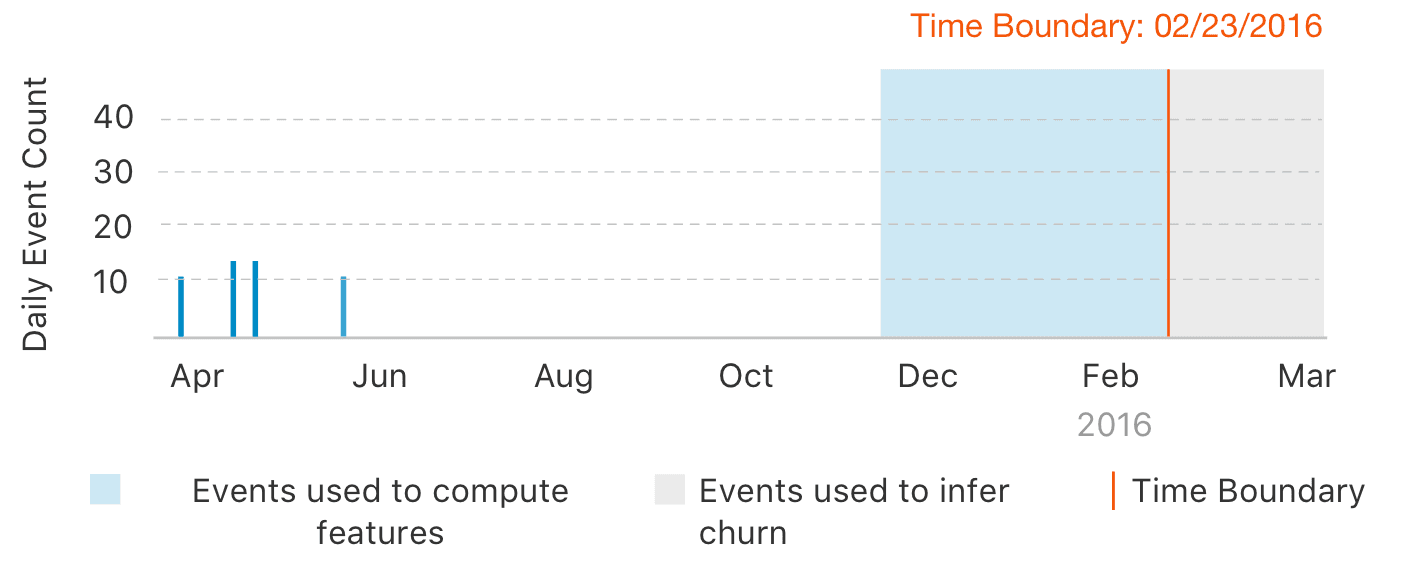
Churn prediction is the task of identifying whether users are likely to stop using a service, product, or website. With Graphlab toolkit, you can start with raw (or processed) usage metrics and accurately forecast the probability that a given customer will churn.
Trong blog này mình sẽ custom lại vn.vitk để có thể chạy như một thư viện lập trình, sử dụng ngôn ngữ python (trên PySpark và Jupyter Notebook).
Jupyter Notebook là công cụ khá mạnh của lập trình viên Python và Data Science. Nếu dùng R, Jupyter cũng cho phép ta tích hợp R kernel vào Notebook một cách dễ dàng.
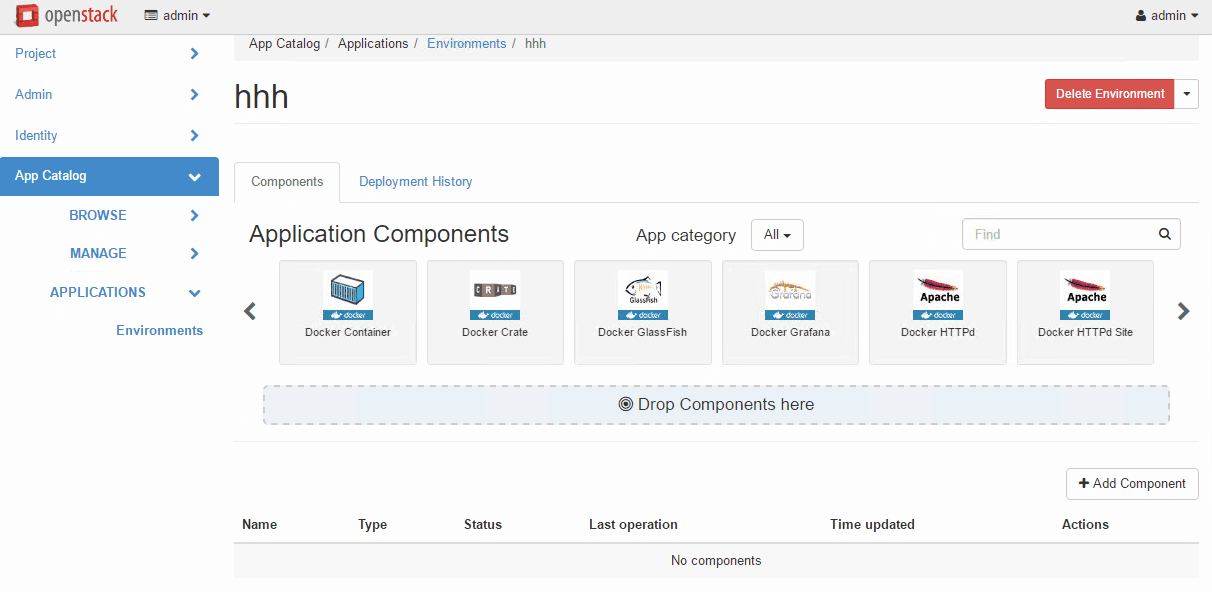
DevStack là giúp triển khai mô hình Openstack cho Developers, có thể chạy trên Single-Machine
Lưu trữ dữ liệu dưới dạng Columnar như Apache Parquet góp phần tăng hiệu năng truy xuất trên Spark lên rất nhiều lần. Bởi vì nó có thể tính toán và chỉ lấy ra 1 phần dữ liệu cần thiết (như 1 vài cột trên CSV), mà không cần phải đụng tới các phần khác của data row. Ngoài ra Parquet còn hỗ trợ flexible compression do đó tiết kiệm được rất nhiều không gian HDFS.
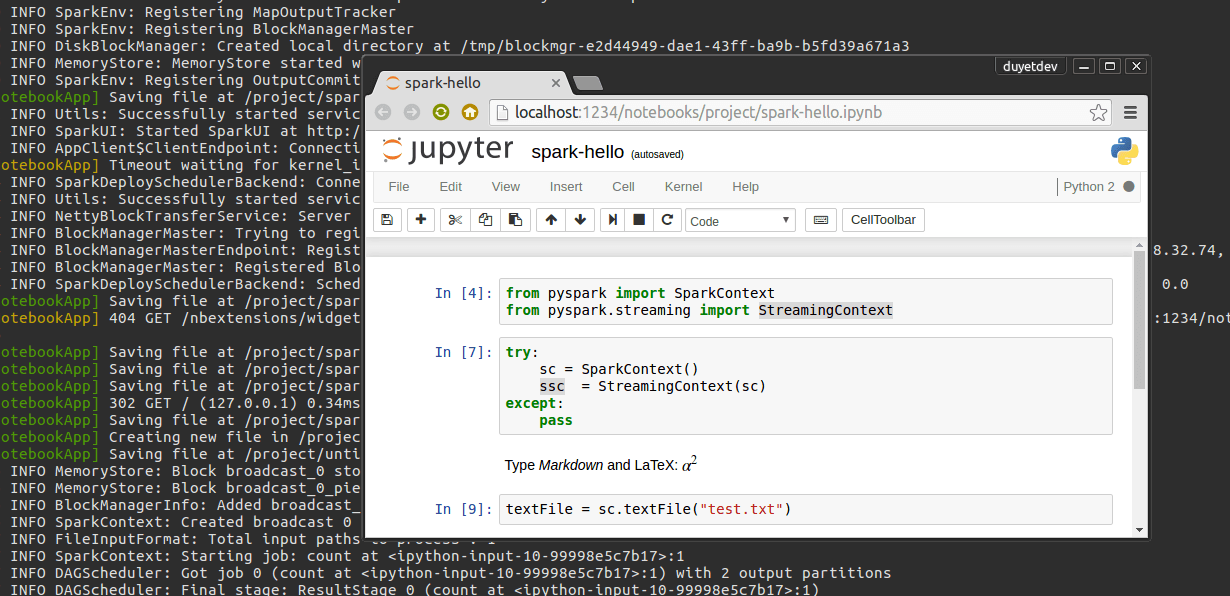
IPython Notebook là một công cụ tiện lợi cho Python. Ta có thể Debug chương trình PySpark Line-by-line trên IPython Notebook một cách dễ dàng, tiết kiệm được nhiều thời gian.
Cài đặt Tensorflow

Cài đặt Odoo trên Ubuntu 14.04/15.04
Hadoop is the standard tool for distributed computing across really large data sets and is the reason why you see "Big Data" on advertisements as you walk through the airport. It has become an operating system for Big Data, providing a rich ecosystem of tools and techniques that allow you to use a large cluster of relatively cheap commodity hardware to do computing at supercomputer scale. Two ideas from Google in 2003 and 2004 made Hadoop possible: a framework for distributed storage (The Google File System), which is implemented as HDFS in Hadoop, and a framework for distributed computing (MapReduce).

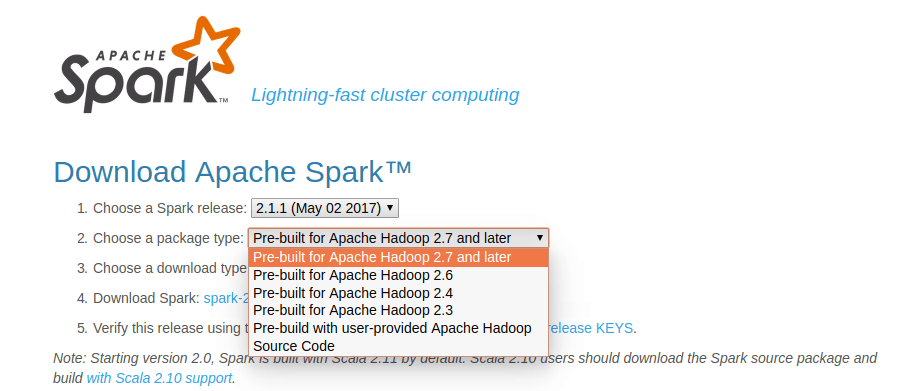
Trong lúc tìm hiểu vài thứ về BigData cho một số dự án, mình quyết định chọn Apache Spark thay cho Hadoop. Theo như giới thiệu từ trang chủ của Apache Spark, thì tốc độ của nó cao hơn 100x so với Hadoop MapReduce khi chạy trên bộ nhớ, và nhanh hơn 10x lần khi chạy trên đĩa, tương thích hầu hết các CSDL phân tán (HDFS, HBase, Cassandra, ...). Ta có thể sử dụng Java, Scala hoặc Python để triển khai các thuật toán trên Spark.
